FSM & DAG
有限状态机 FSM,侧重于描述系统的 状态 和 行为,描述状态间的 转换关系,可有环;
状态机的元素:
- state 状态,任意时刻,状态机都只能处于某一个状态;
- event / transition condition 事件:即事件驱动的事件;
- transition 转移:状态转移的过程(状态转移方程);
- action 动作:到某个状态需要执行的动作;
如 tcp 的状态机、线程的状态机;(这里就不展示了)
有向无环图 DAG(directed acyclic graph),侧重于描述节点(状态)间的 依赖关系 和 层次关系,用于描述复杂流程,经典如 任务调度、编译优化、文件过算子的流程等,灵活性较好(易于添加任务);
注:文件过算子:风控场景下,一个文件通常可能命中多个算子策略,如广度上可能需要过色情、伦理算子,深度上 算子间也可能组成一个 DAG,如大分类到若干小分类,色情、儿童色情、低俗、性暗示等;(这里只是举例,非真实过检流程)
与流批处理系统对比
第一反应,spark 的血统图其实就是 DAG 的一种实现,RDD 可以看作顶点,map、filter、join、collect 等操作可看为边;
目前本人还不算太熟悉 spark 和 flink,但两者应该都是基于 DAG 模型,本质区别还是在流批上,即 批处理 中每个 action 触发后构建 DAG,并分多个 stage 并行执行,而 流处理 是以连续流的形式处理数据(目前体感只是批处理会延迟批量处理);两者中间状态维护思想差不多,spark 依赖于 persist 操作 和血统,flink 应该是依赖于快照(checkpoint);
除了调度层面,再补充下其他方面的区别,如:
- 流批系统主要负责数据计算任务,经典的 ETL 等;自实现 DAG 倾向处理 轻量 service 或者脚本任务(即非数据处理类逻辑);
- 自实现 DAG 考虑的点肯定不充足,顶多可支持任意类型任务在指定时间在哪台机器执行的程度,并且可能对于个人而言可控性更高?,流派还是主要用于处理大数据?
注:此处的 非数据处理类 逻辑不完全等同于 非 CPU 密集型任务,简单举个反例:OCR 或 视频无关键帧时的截帧场景,这两不是数据处理类,但 cpu 占用也很高;
拓扑排序
对于 DAG 中,每个有向边(u, v),在序列中 顶点 u 在顶点 v 之前;
Kahn 算法(bfs):初始化一个队列,将所有入度为 0 的节点入队;从队列中获取一个节点,将其添加到拓扑排序的结果中,并移除其所有出边;对于每条被移除的变,如果对应目标节点的入度变为 0,则将节点入队;循环直到队列为空;(注意排除环)
dfs:递归返回时的顶点入栈,最后依次从栈中弹出的顺序即为序列顺序;
eg:kahn:
package main
import (
"fmt"
"strconv"
"strings"
)
func main() {
var n, m int
fmt.Scanln(&n, &m)
inDegree := make([]int, n)
adjList := make(map[int][]int)
for i := 0; i < m; i++ {
var s, t int
fmt.Scanln(&s, &t)
inDegree[t]++
adjList[s] = append(adjList[s], t)
}
queue := make([]int, 0, n)
for i := 0; i < n; i++ {
if inDegree[i] == 0 {
queue = append(queue, i)
}
}
result := make([]int, 0, n)
for len(queue) > 0 {
cur := queue[0]
queue = queue[1:]
result = append(result, cur)
for _, next := range adjList[cur] {
inDegree[next]--
if inDegree[next] == 0 {
queue = append(queue, next)
}
}
}
if len(result) == n {
strs := make([]string, n)
for i, num := range result {
strs[i] = strconv.Itoa(num)
}
fmt.Println(strings.Join(strs, " "))
} else {
fmt.Println(-1)
}
}
如:Airflow,通过 DAG 实现任务调度(依赖 元数据库 管理元信息和中间数据):
注意:任务需要完成什么动作 && 任务需要依赖什么任务
步骤:
- 将复杂任务拆分为多个小任务,即 将可独立的小任务拆出来;
- 根据小任务间的依赖关系进行调度,拓扑排序 or 优先级队列(元素为 小任务 : 依赖关系的集合)实现;
- 当所有小任务完成后,将结果合并为一个完整任务(如通过 hook 实现);
对于 xxl-job 目前看下来原生不支持 DAG 任务编排,原本的调度模型以独立任务为单位,支持串行、分布式执行、失败重试、线性排序(完成任务后,可自动触发后续任务,链式)
调度系统
时间管理(time management),如考虑任务计划、优先级,是否需要实时调度,资源结合 LB 进行分配等;
范围(scope),如任务的类型,调度系统的架构,支持的功能(如日志、监控告警等),系统的可伸缩性和扩展性,也可能涉及权限管理;
能力
- 支持用户提交任务(注册 handler,如脚本或者常驻的轻量服务);
- 由调度者主动启停任务(如 cron 触发);
- 任务产出:
- 持久化到 db,由可视化平台或者数仓再去拉取进一步展示 or 处理;
- 数据分析场景中,就比如 spark 等业务中,存在任务依赖关系,可转换为 DAG 关系;
健壮性
- 可扩展性
- 可用性 & 可靠性
即依赖于 db + FSM;
调度 model 可能的考虑:
- job id
- owner id
- 二进制可执行文件下载 url
- 任务元信息获取 url(或者是 json 格式的 task_info)
- 任务执行结果下载 url
- status
- 重试次数
对于 任务的 FSM:
ready -> waiting -> running -> success
| |
retry <- failed -> abort/delay queue
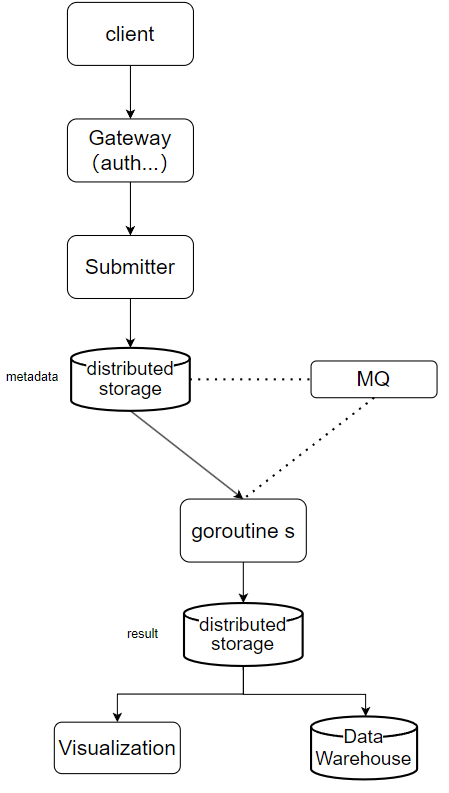
- mq 可考虑存内存型或磁盘型(即是否无状态,但磁盘型的要考虑数据一致性,一种简单的可能是独立任务仅允许通过 mq 进行消费执行,todo)(同理,mq 可考虑换为一个小 scheduler,发布任务给 worker,设计和 MR 的scheduler 类似);
DAG 构建简单任务调度系统的组件考虑:Vertex(包括行为),Graph(流程管理),Context(上下文)、Config(生成 Graph)等;
进一步案例分析:广告平台化的探索与实践
施工中…