Embedding 即向量化;
利用计算相似性,找最相似的相关对象:
search 搜索
clustering 聚类(最相似的一组)
recommendations 推荐(最相似的几个)
anomaly detection 异常检测(识别出相关性很小的异常值)
diversity measurement 多样性测量(分析相似性分布)
限制:时效性、安全性、token长度;
eg 用户 query 流程:
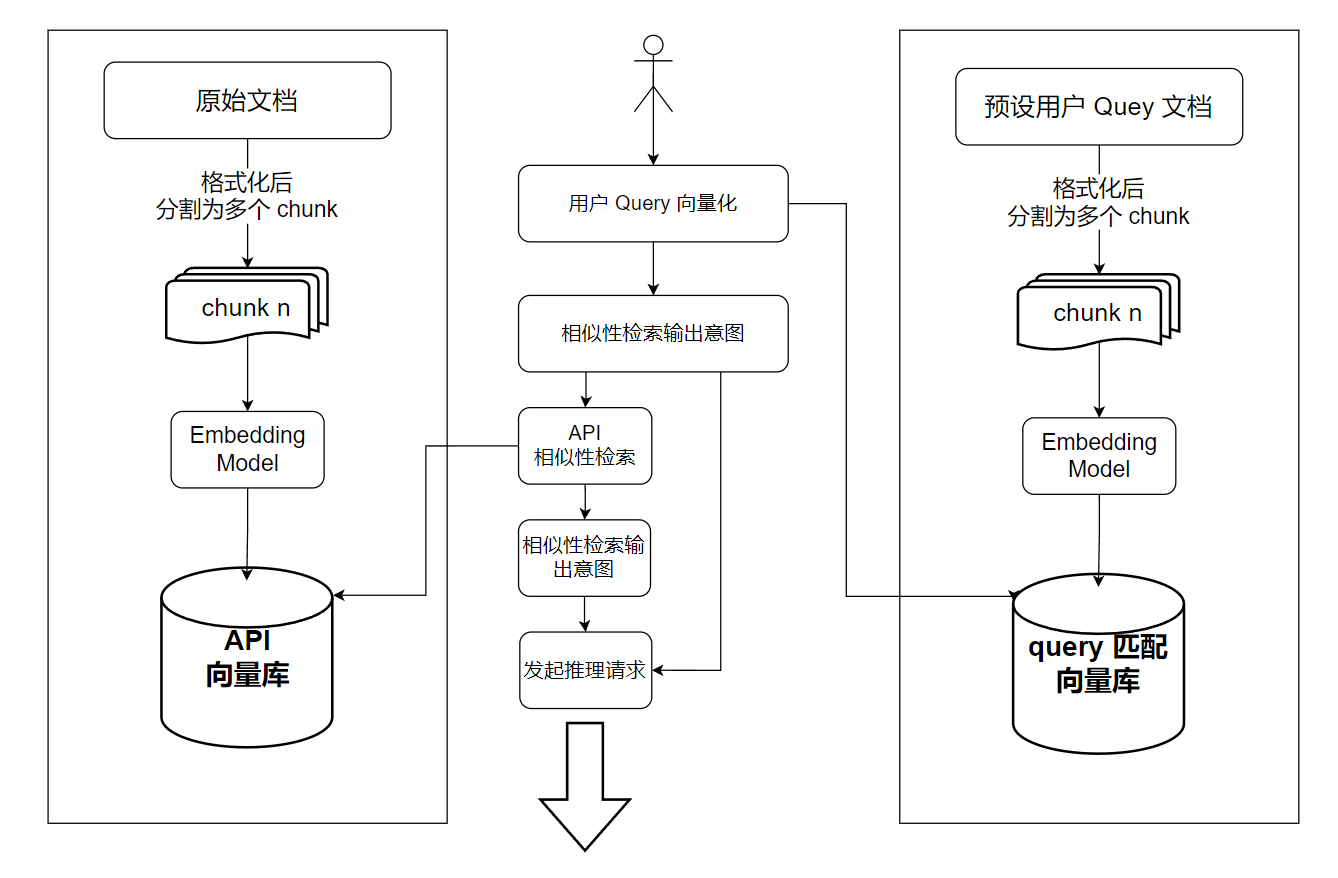
切片:chunk
为什么需要切片:
1)模型对文本向量化的token长度是有上限的,token长度的限制主要是受限于计算复杂 切片:
2)token 越长意味着越高的相似性算法复杂度,资源消耗的越多,计算的耗时越长;
方案一:使用 chunksize 切割,明显容易截断上下文;
方案二:基于MD的标准格式进行切分,使用LLM将文本提取出关键词进行向量化(用户 query较短,如果和完整文本做相似性匹配时召回率估计很低),并且用LLM对query进行关键词提取;
注:也结合具体的业务场景分析,如菜谱的检索,可考虑向量化菜品的原料+菜品本身性质等方案;
向量化
Tokenization:
将文本切分为 token;如基于预定义的规则(注:分词是分 token 的子集),或者基于统计的方法+机器学习确定分词方法;
word embedding:
使用 密集向量 表示 词语 的方法,目标是捕获词语之间的语义联系;
如:矩阵分解方法、基于 Graph 的 embedding 方法、基于 内容 的 embedding 方法(如 word2vec[1](看上去有点过时了)、GloVe、FastText)和动态向量 embedding(如 ELMo、GPT、BERT);
特点:
1、低维稠密向量:
每个词被表示为一个低维的稠密向量,几十到几百;
通过训练神经网络学习得到,可捕获语义上的相似性,相似的词在向量空间中更加接近;
2、上下文信息:
训练过程中会考虑上下文信息,可捕获词语的多种语义;
相似性匹配:
- 欧几里德(欧式)距离
- 反应向量的绝对距离 + 适用于考虑向量长度的相似性计算;
- 高维效果差;
$d(\mathbf{A}, \mathbf{B}) = \sqrt{\sum_{i=1}^{n} (\mathbf{A}_i - \mathbf{B}_i)^2}$
注:A、B 是两个 n 维向量,Ai 和 Bi 分别表示 向量 A 和 B 的第 i 个分量, $d(\mathbf{A}, \mathbf{B})$ 表示向量 A、B 间的欧几里得距离;
- 余弦相似度
- 反应向量之间的夹角余弦值 + 适用于考虑向量方向的相似性计算,对长度不敏感,即适用于高维向量的相似性计算,语义搜索和分档分类等
$\text{cosine_similarity}(\mathbf{A}, \mathbf{B}) = \frac{\mathbf{A} \cdot \mathbf{B}}{| \mathbf{A} | | \mathbf{B} |}$
- 点积
- 反应向量间的点积值,兼顾长度和方向,但是也因此对高维向量的相似性计算可能有误差;
$\mathbf{A} \cdot \mathbf{B} = \sum_{i=1}^{n} \mathbf{A}_i \mathbf{B}_i$
相似性搜索
需求:在海量数据中找到最相似的 TopK 个向量;
- 并行化处理,将向量分桶,并行匹配;
- 降低向量维度;
- 缩小搜索范围,即利用聚类算法一次性过渡大部分距离较远的簇(如 K-Means[2]);
3、相似性匹配; 4、向量数据库;
备注
-
word2vec 训练模式:
- CBOW:通过上下文来预测当前值,即一个句子中扣掉一个词,预测这个词是什么;
- Skip-grom:用当前值预测上下文,即反过来,词猜前后的词;
-
K-Means:
- 简单来说,流程:每层循环中,将在空间中分布的点(向量)分桶,再从桶中找出新的中心点,此时中心点视为新的“向量”,开始新一轮循环,直到完成 K 个簇的分配 并计算出每个簇的中心点;
参考资料
240413 注:不太正能量的自我吐槽(虽然这个技术博客也不知道会有人认可吗,或许就是记录下我在学生生涯末期的挣扎和心态吧);
碎碎念一下,2025-03-31,wwww
回顾回顾 ssss:
- 懒惰,没有榨干晚上下班后的时间用于刷算法,周末刷题的强度也低,高看自己 10min 左右做到 1a 的能力了;治:有空的时候多刷题保持题感,减少手残情况;
- 胆小,面试时不能充分活动脑子,哪怕对于不确定的地方 也要给出自己的看法与解法,而不是语无伦次 不敢下推断;治:抽时间复习,加强自信,将熟悉的知识尽可能融会贯通;遇到基础问题、扩展性问题,如果第一反应给出的答案不够好,一定一定要冷静,让大脑去 思考 而不是发愣,只有 思考 才可能找到更好的答案;思考 动脑 思考
- 以周为粒度进行复盘,尽可能提早发现自己的不足,抓住任何可以提升能力的机会,多了解,多写代码,多思考,持之以恒 细水长流,在秋招之时 尽可能弥补和 高学历高技术力同学 间的差距 :)
keep on
细水长流
二更,2025-04-13,wwww
没啥面试机会,官网投貌似概率小,boss 试试,我是不是要去背八股、刷算法 才能有效提高不被干掉的概率吗,麻了,有面试机会才有机会体现出我的能力,才有可能走到最后(废话);
实习能找到一些工程亮点,但我没机会分到这部分的需求实际自己去干,只能看看代码、文档,在面试中说这部分的内容 不知道会不会被质疑,只能靠自己慢慢摸索,边界情况和倒推设计原因了;
目前分到的需求都是业务强相关,基本一版设计方案就够了,后面只是微调业务细节,感觉学不到东西,但学历好的大佬可以无缝衔接,哥们一边实习一边面 确实感觉状态一直不能拉满(算法八股肯定没竞争对手练的多了,只能尽力而为了),但离职再面 容错就降低了 心态不知道能不能一直保持良好;
也蛮羡慕有学长帮忙直推或者多少能指点(褒义)的佬,孤军奋战感觉会想漏很多东西,有点快陷入
恶性循环了:–start
面试排序不够,拿不到 offer / 甚至没面试
–因为->
实习项目等直接体现的工程能力不拔尖,我也不知道如何向面试官展现我的能力 或者 算法没别人 a 的多 a 的快,或者有对口经历 更好学历的大佬把我干掉了; –因为->
真不想考研,我也不认为考研后的读研生涯能依赖导师学出什么我现在学不会的知识(不是我有没有‘资格’学,而是我能不能学会),我更喜欢做有意义的事,对能力成长有益的事,考研可以间接证明知识学习能力,但我文科是真,,并且既然是一次性的考试并且竞争人数也不少,即使有一定的学习能力 甚至是还算优秀的学习能力,也不可或缺的需要 刷题,我也不适应这种重复性的‘脑力劳动’,除了让考试分数更高以外,真的有意义吗,当然我也认可这种也能反映一个人的能力,只是我个人不喜欢 在这种情况下先淘汰我吧:(
实习分到的需求虽然也有大需求,但貌似不能体现出 广义上的工程能力,只是在考虑在业务背景下,利用 mysql、cache、mq 等核心组件,外加基础的代码控制流编写,完成业务(虽然这是正常后端开发),但毕竟现在竞争人非常多,排序的时候这部分的能力貌似也不会被当作加分项,就算代码本身的控制流写的还不错(当然肯定没经常干开源的佬写的优雅),应该也被默认为 人人都会的基础,但我业务真的就是做这部分,个人感觉也不能被称为无价值吧,但貌似事实上对于面试的帮忙而言 聊胜于无?
听正式员工的技术评审时 即使我能 get 到设计的点,但是毕竟终究不是自己全流程跟着并且负责需求的开发,我和同组成员或者 mt 聊的时候还能侃侃而谈,聊一下细节和设计原因,但是要我在面试中 单方面输出,我是真不太敢,万一嘴瓢说错细节,并且如同向领导汇报般的状态,怕被打上 ‘技术基础差’ 的标签;
也希望可以去其他大厂换一个场景,多学习多写有价值的代码(或工程或业务),扩展视野,能力都是一行行代码,一篇篇文档写出来的,为秋招增加一份 offer 的可能性?但实际上面试机会也少,剩余时间多投投,多约面,希望有对的上脑电波的面试官;实际上到现在还没有好的机会;
–因为->
面试排序不够,包括 广义上的能力和学历;
–over
说实话,最可惜的是暑期第一次面试某大厂,那个岗位还算对口,但是 leader 面时,面试官对于实习做的业务需求的提问,我没能更有自信的回答,后面复盘的时候,明明我提供的方案肯定是可行的,但是因为我自己面试时忘记了真实的方案,导致自己给出的解法 不敢保证是真实解法,从而有点畏畏缩缩,但是面试官应该也想看我的思路,但是我当时满脑子都是在想我给的方案会不会有边界情况的 badcase,导致回答的不够好;并且因为是第一次面,那个时候实习也忙需求,导致只有周末一点时间刷算法,结果最后算法在最后调试阶段,没ac,补充说了思路,总之复盘的时候确实感觉是我发挥的不够优秀,后面就每天下班后刷五六道算法再休息,并且重新复盘实习需求涉及的方方面面设计,即使那部分不是我负责的我也要搞明白,面试的时候应该自信点,抓住面试机会;
我还能怎么办?怎么有效提升自己?不可能有人教,只能靠自己,搞技术的初衷也是靠自己能有碗饭吃,从 0 到现在,也是自己摸索,在网上分辨有效和无效的信息,让自己所谓 变强;没办法,还是要吃饭的,也不是家财万贯,和大多数人一样经历跌宕和起伏,希望能持之以恒,做感兴趣的工作,找到适合自己的开发定位,我还能保持良好的心态到明年吗哈哈哈;