背景
CVP:大模型+向量数据库+提示词:
缺陷,实际上大模型没有记忆的能力,目前的上下文是通过一次性发送给大模型,即一般都有tokens的限制,大模型只能『记忆,限制大小的上下文;
因此引入向量数据库,核心思想是将文本转换为向量(如将长文本或多个文本拆分为小的、可管理的chunk,并将chunk转换为向量),然后将向量存储在向量数据库中,供大模型按需检索和处理(如同大模型的『记忆』);
向量化搜索
非结构化数据(音频、图片等)转换为向量(过程称为 Embedding,即向量化)后,对向量(结构化数据)进行检索 从而找到对应实体,或者可以说向量检索就是 非结构化检索,典型的例子就是:人脸识别、推荐系统等;
当然转换的准确是基础,特征抽象太差(数据集脏),检索效果也不能优化到可用;
可总结出三种思想:
- 空间划分法,如聚类、KD-Tree,检索时 快速定位到小集合,减少需要扫描的数据点的数量;
- 空间编码和转换法,如 PQ 等,将数据集重新编码或变换,映射到更小的数据空间中,从而减少需要扫描的数据点的数量;
- 近邻图法,如 HNSW,将数据预先建立关系图,加快检索时的 收敛速度,同样因此减少需要扫描的数据点的数量;
技术挑战:
标签 + 向量的联合检索,注意,不等于 标签(bool)检索 + 向量检索;流式索引的在线更新;超大规模索引的精度和性能;分布式构建和检索;多场景下的适配;
多模态
详细见:MLLM
涉及多种不同类型数据(文本、图像、音频等)的处理和联合查询,不同类型数据会通过不同的模型进行向量化,形成可以进行相似度匹配的特征向量;(模态 是指数据的不同类型或表现形式)
向量化后,不同模态的数据转化的高维向量,它们在表示上还是存在差异的,因为:
文本、图像、音频的本质不同:每种模态有自己独特的结构和信息表达方式。如 文本:语言信息,图像:空间和视觉特征,音频:时间序列上的声音信号;
向量化方法不同:是不同的处理模型,如,文本:语言模型(BERT、GPT等)进行向量化;图像:卷积神经网络(CNN)生成向量;音频数据:特征提取和深度学习方法来生成向量;
多模态向量检索:处理和联合查询不同模态的系统;
跨模态学习:将不同模态的向量映射到一个共享的嵌入空间,以便它们能够互相比较和匹配。这样可以支持文本和图像之间的相似度查询;
联合查询:一个检索系统能够同时处理多个输入模态,返回最相关的数据;
Faiss
Faiss 不是一个向量数据库,它只是一个引擎,在内存中检索向量;
不能存储真实数据,只存储 ID+向量,因为会全加载进内存检索(faiss);
优势:
- 相似性搜索:高效搜索 大规模向量集合(允许任意大小) 中与查询向量最相似的向量(相似度检索、聚类),即使内存不足也可以检索,应用于图像检索、推荐系统、自然语言处理和大数据分析等领域;
- 多索引结构:包括 Flat、VF、HNSW、PQ、LSH 等索引(选择依据:空间、时间复杂度、召回率);
- 提供辅助代码用于 评估和参数调优,优化具体的搜索模型,提供性能和准确性;
- 利用多核处理器(CPU)和 GPU 加速搜索操作:
- 支持 py 和 cpp, 开源可免费使用和修改;
向量 -> 创建索引 -> 添加数据到索引 -> 检索;
允许索引从磁盘存取;(故可以提前将索引构建在 文件系统 里面)
milvus
milvus 底层也是调用 faiss,实现包括:
- 权限管理;
- 索引管理(load、release、partition,即建库建表键索引)
- CURD 的 API接口;
- 数据维护(存储、备份、迁移)
- 高可用(集群分片管理,支持读写分离、水平扩展、动态扩容,支持超大数据规模)
- 治理(监控等)
- GPU(Nvidia)索引加速 + 查询加速;
索引类型:
- IVF:faiss的,和 milvus 自研的 IVF;
- Graph:自研的 NSG 索引,faiss 的 HNSW;
- Tree & Graph:集成微软的 SPTAG;
官方架构图:
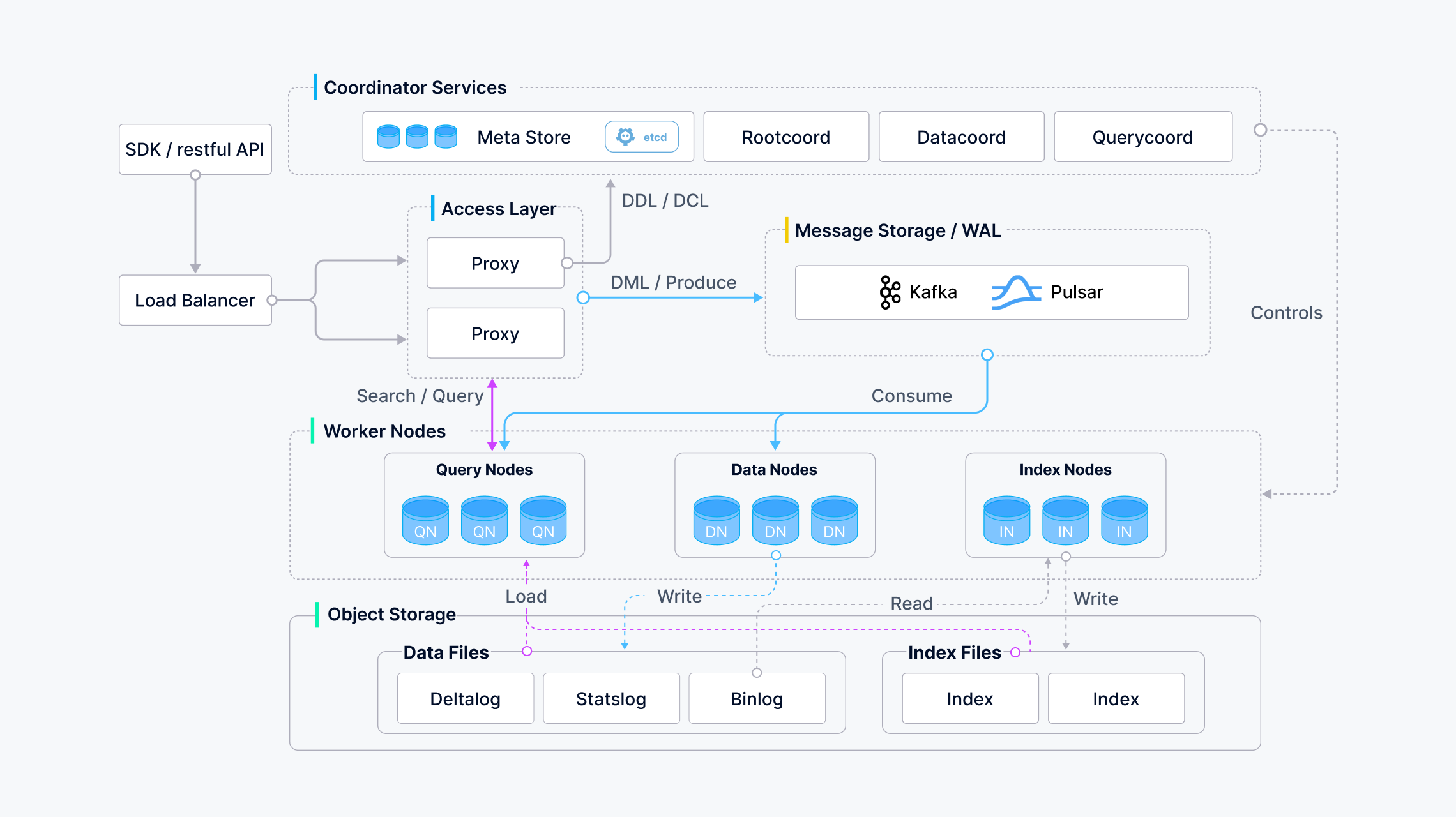
Access layer: 接受请求,验证请求参数和合并返回结果;
Coordinator service: 负责分配任务,集群的拓扑管理、LB、生成时间戳、数据声明和管理;
Worker nodes: 工作节点;
Storage: 持久化db;
主要的模块:
proxy:验证请求参数和合并返回结果;
coordinator service:
Root: 处理 DDL 和 DCL 请求,如创建(删除) colection、partition、index,及 TSO(timestamp Oracle)管理;
Query: 管理查询节点的拓扑结构和 LB,以及将 growing(表示数据段正在接收新数据的写入或者更新)的 segment(数据段)切换到 sealed(表示数据段已经稳定,不再接收写入或更新);
Data:管理数据节点的拓扑结构,维护元数据,负责触发 刷新、压缩和其他后台数据;
操作:
1) 分配 segment 数据; 2) 记录分配空间及其过期时间; 3) segment 刷新的逻辑; 4) 哪些 channel 被哪些 Data node 消费,需要一个 data 做整体的分配;
Index:管理索引节点的拓扑结构,建立索引,维护索引元数据;
meta storage (etcd): 存储 collection schema,节点状态、消息消费检查点等元数据快照,etcd 作为命名服务和健康检查;
worker nodes:
data node:订阅日志代理获取增量日志数据,处理变更的请求,将日志数据打包成日志快照,并存储在 OSS 中;
index node:建立索引文件,存储在 OSS 中;
query node:订阅日志代理检索增量日志文件,将他们转换为 growing segments,从对象存储加载历史数据,并在向量数据、标量数据间进行混合搜索;
object storage (Local File System. minig. s3、 Azure Blob):
log snapshot;
data file;
index file:标量数据、矢量数据的索引文件;
ES
向量的搜索 是建立在 Apache Lucene HNSW 的基础上,即 Lucene 9 中原生 ANN(近似最近邻);
额外的参考资料:节省 90% 存储!源码级揭秘腾讯云 ES 向量搜索的优化之道
以下描述基本出自官网:
KNN 插件
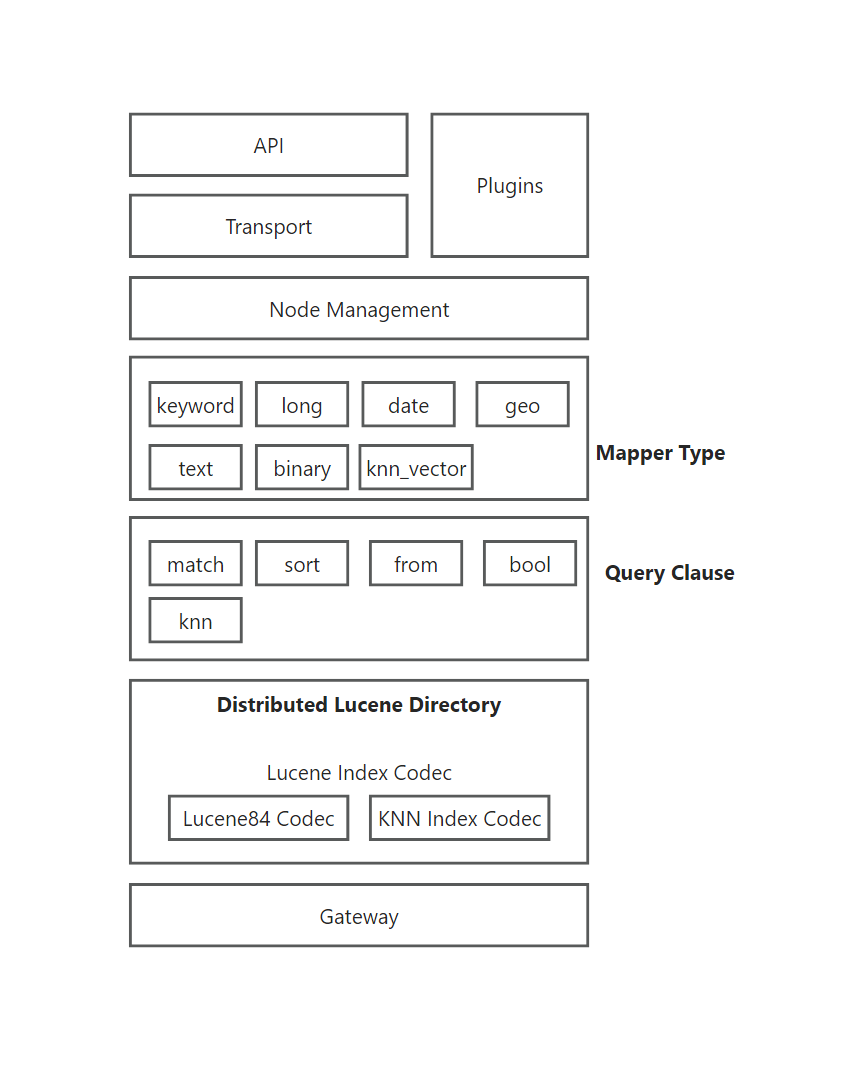
- Transport:负责 ES 集群内节点间的通信,处理请求的发送和接收;
- Node Management:管理 ES 集群中的节点,包括节点健康检查、负载均衡等;
- Mapper Type:用于索引文档时定义数据字段的类型,字段类型:
keyword等,knn_vector是新增的字段类型,存储支持 KNN 搜索的向量数据类型; - Query Clause:
match等 是查询时可能使用的各种条件,knn查询允许通过向量相似性查找数据; - Distributed Lucene Directory:ES 使用
Lucene来存储和检索数据;图中展示了几个与Lucene索引相关的编解码器:Lucene84 Codec是传统的索引编解码器;KNN Index Codec是支持 KNN 插件的特殊编解码器,用于存储和处理 KNN 向量数据; - Gateway:用于处理数据的持久化与恢复,是数据存储与检索的核心组件;
ES 分片由段组成,段是索引中的内部存储元素;
近似最近邻(kNN)搜索的底层工作机制:每个段的密集向量都会存为 HNSW 图,ES 可以并行查询处理多个段,段合并时 HNSW 也会合并;因为构建 HNSW 图的成本较高,通常可增加索引(降低构建单图成本),如果当客户端批量请求超时,可强制将索引合并到单个段 改善 kNN 的搜索延迟(为降低延迟,提升构建成本);
8.x 以上的索引类型为 dense_vector,浮点型向量;
段:索引中包含的文档集合,包含索引的元数据,如字段映射、分词器设置等,不可变数据结构,倒排索引,可理解为 LSM 中写入磁盘的一个单位;
Proxima
阿里自研的向量检索内核,是通用化的向量检索工程引擎,实现了对大数据的高性能相似性搜索,单片索引十亿级别下 高准确率、高性能的索引构建 + 检索;
Jina
神经网络搜索,通过结合 深度学习和人工智能搜索能力 实现全内容搜索(全模态);
Jina hub
- 支持通过 Pod(预构建镜像)快速构建和部署 ai 工作流;
- 支持多种 AI 模型、向量数据库、Evaluation(评估+改进);
备注
- BLAS:用于高效执行基础线性代数操作的标准库,如矩阵乘法、向量点积等;
-
IVFFlat:聚类 + 子空间搜索,如先使用 k-means 聚类算法,将数据分为多个簇(clusters),每个簇代表一个子空间(用一个簇中心 centroid 表示),子空间内的数据通过 倒排索引的方式维护;
- 构建过程:对于每个数据点,计算它与所有簇中心的距离,将其分配到距离最近的簇中;
- 查询阶段:需要查询的向量 到每个簇中心计算距离,然后选择距离最小的几个簇(可配),在这些簇中查找最相似的向量(最近邻);
- 倒排索引 eg:[簇:数据点1, ... ,数据点n]
- 参数:nprobe 控制搜索范围;
- LSH:用于高维数据的近似最近邻搜索,通过 hash函数 将相似的向量映射到相同或相似的 哈希桶内;可做到无监督构建索引,无需重新训练索引,可在线实时添加,查询因为是哈希操作,所以速度非常快;但明显向量的信息在映射的适合会有损失,召回率低;
-
PQ:全称 Product Quantization 积量化,将高维向量分解为较低维子空间上的多个子向量,对于子向量使用量化器进行聚类(通用如 k-means),完成后一个簇生成一个码本(Codebook)。映射索引是子向量在码本中的位置;(节省空间,不需要存原始浮点数)
- PCA 是通过线性变换将数据投影到较低维度的空间,同时尽可能保留数据的方差,而 PQ 也类似,不过是通过非线性分解对数据进行近拟
-
HNSWFLat:基于 HNSW 图算法的实现,NSW 近邻图中,有两种边:short-link(用于搜索最近向量)、long-link(在搜索初期提高搜索效率);
- 构建过程:每次在图中插入节点 v,寻找 k 个最近的节点 x,让 v 和 x 之间产生边、插入时产生 short-link 边、当新的 距离更近的节点加入,且此时 short-link 不再是最近的 k 个,则转变为 long-link;
- 查询阶段:从随机挑选的节点开始,通过 long-link 快速找到 query 对应附近节点,再通过 short-link 找到满足查询的节点;
-
HNSW(Hierarchical Navigable Small World,超最小世界导航 / 近邻图算法) 是分层的,顶层最稀疏,底层最密集,有点类似跳表,且近邻图算法无需预训练,可实时增删节点,高召且查询性能良好,缺点是构图需要占用大内存,分布式化比较麻烦(节点间的图貌似连不起来);
- 每一层都是一个小世界,经典 空间换时间;
未了解:Proxima、vearch、Jina;pinecone(单)、annoy(单)、vespa、chromadb
密集向量:所有维度都有值(通常为实数),用于表达固定长度的特征,适合计算相似性度量和进行高维检索;
稀疏向量:大多数维度值为零,通常存储为一个 KV对列表,只记录非零值的维度和值;适合记录高维度但是数据稀疏
KD-Tree:
- 用于组织k维空间数据的二叉树结构,每个节点代表一个 k 维点,树的分割依据是每个维度的值;
- 在构建树时,每个节点根据某个维度的值将数据集分成两部分,通常使用中位数来划分。第一个节点基于第一个维度,第二个节点基于第二个维度,依此类推,当到达第k个维度时,回到第一个维度进行划分,直到数据集为空或满足某些停止条件(如节点数较少);