2023年
8月
8日 416.分割等和子集
从题目描述中,分割的子集有且仅有两个,从而分析出分割后的子集元素和,一定等于数组元素和的一半;考虑使用01背包解决;物品重量为元素的数值,价值也为元素的数值;最后判断最大物品容量是否等于物品价值,等于即为true。
9日 1049.最后一块石头的重量 II
与416题类似,题意可分析为,将集合分为两个,并使两者差值尽可能小,易得最小的情况即为416题返回true的情况,即差值等于0
10日 494.目标和
入题思路很重要:假设sum为数组内元素和,加法总和为x,故减法的绝对值的总和为(sum-x),易得x-(sum-x)=target;解得x=(sum+target)/2,分析该式子,sum和target均为整数,所以易得出当(sum+target)为奇数时,不存在满足题目条件的x;
dp[j] 表示:填满j(包括j)这么大容积的包,有dp[j]种方法
递推公式:dp[n]能装下的方法,为dp[n-1]到dp[0]的累加(勉强)
11日 474.一和零
此题包含两个维度,分别为’0’的重量和’1’的重量,相比普通01背包多了一个维度,所以滚动dp数组此时为二维数组;在两层for循环中,第一层是物品价值的遍历,第二层是背包容量的遍历,两层中多了一个计算物品重量的过程(计算字符串的’0’和’1’的数量);递推公式中,加上的物品价值为1,是因为题目需要最多个满足题意的字符串,所以加1代表加一个满足题意的字符串。最后返回题目允许装载最多0和1的dp[m][n]。
12日 518.零钱兑换 II
同494递推公式,改变遍历方法即可
15日 377.组合总和 Ⅳ
先遍历背包后遍历物品得到的是排列数
先遍历物品后遍历背包得到的是组合数
爬楼梯也可看做与此题一样,一次可以爬几层楼梯即为几个整数,楼顶即为目标整数
10月
9日
53.最大子数组和
主要考虑dp时,前一个状态如果为正,那么加上当前状态后可看最最大子数组的部分和,即看作当前状态的值和当前状态加上前一个状态的值哪个大,如果前一个状态为正,后者一定大于前者;
由于最大子数组和的子数组可能在整体数组中间,故dp[nums.size()-1]的值不一定是最优值,所以需要一个ans记录历史最大dp[i]。
11日
92.反转链表 II
先找到开始反转的左边界,当前节点记录左边界,左边界前一个节点用pre记录,每次反转都是将当前节点的下一个节点移到pre的下一个节点处,单此操作为:
1、先记录当前节点的下一个节点next;
2、将当前节点指向next的下一个节点;
3、将next节点指向pre的下一个节点;
4、最后将pre指向next节点。
重复该循环(right-left)次,即为答案。
12日
121.买卖股票的最佳时机
动规写法:找差值,找区间最大和
遍历写法:记录maxp和minp,如果是在历史最低点minp买进的,那么今天卖出能赚多少钱(一开始股票开始跌的时候,maxp一直为0)?赚的最大值为maxp,当考虑完所有天数之时,我们就得到了最好的答案。返回maxp即为答案。
122.买卖股票的最佳时机 II
动规:dp定义状态 dp[i][0] 表示第 i 天交易完后手里没有股票的最大利润(上升时更新),dp[i][1] 表示第 i 天交易完后手里持有一支股票的最大利润(下降时更新)(i 从 0 开始)。
使用max更新dp,如果今天价格大于昨天价格,则此时卖出昨天的股票加上累计赚的钱一定大于昨天直接出售股票后一共能赚的钱;如果今天价格小于昨天价格,则此时(昨天赚的钱-今天买入的价格)一定大于(前天赚的钱-昨天买入的价格)。
13日
123.买卖股票的最佳时机 III
动规,与2不同的是,此时一共有五个状态,分别是:没有持有股票,第一次持有股票,第一次卖出股票,第二次持有股票,第二次卖出股票,所拥有的金额。
初始化的时候,n个持有股票的变量等于第一天买入股票(即-prices[0])(可视为同一天内进行n次买卖,买入后金额为-prices[0],卖出后金额为0),卖出股票等于0;转移方程分别为,第一次:持有:上一个状态和当前天数的股票价格取负数中的最大值(对应买的最低价股票);卖出:上一个状态和当前天数加上第一次持有股票时的金额中取最大值;……;第n次:持有:上一个状态和当前天数的股票价格取负数加上第n-1次卖出后拥有的金额中取最大值;卖出:上一个状态和当前天数加上第n次持有股票的金额中取最大值。
最后返回最后一次卖出的金额即为答案。
class Solution {
public:
int maxProfit(vector<int>& prices) {
int Fbuy = -prices[0];
int Fsell = 0;
int Sbuy = -prices[0];
int Ssell = 0;
int Tbuy = -prices[0];
int Tsell = 0;
for (int i = 1; i < prices.size(); i++)
{
Fbuy = max(Fbuy, -prices[i]);
Fsell = max(Fsell, prices[i] + Fbuy);
Sbuy = max(Sbuy, Fsell - prices[i]);
Ssell = max(Ssell, prices[i] + Sbuy);
Tbuy = max(Tbuy, Ssell - prices[i]);
Tsell = max(Tsell, prices[i] + Tbuy);
}
return Tsell;
}
};
14日
188.买卖股票的最佳时机 IV
同三的描述,需要注意几个点:
1.数组的索引增加时不能越界;
2.外层i循环用来遍历天数,内层j用来刷新不同买卖次数的状态
class Solution {
public:
int maxProfit(int k, vector<int>& prices) {
int kk[200]={0};
for(int i=0; i<2*k; i+=2)
{
kk[i]=-prices[0];
kk[i+1]=0;
}
for(int i=1; i<prices.size(); i++)
{
kk[0]=max(kk[0], -prices[i]);
kk[1]=max(kk[1], kk[0]+prices[i]);
for(int j=2; j<2*k; j+=2)
{
kk[j]=max(kk[j], kk[j-1]-prices[i]);
kk[j+1]=max(kk[j+1], kk[j]+prices[i]);
}
}
return kk[2*k-1];
}
};
309.买卖股票的最佳时机含冷冻期
主要分析出四个状态:已经买入,卖出且过了冷冻期,今天卖出,今天冷冻期
已经买入 的前状态可以是: 已经买入 和( 今天冷冻期 or 已经买入中的最大值 )中的最大值;
卖出且过了冷冻期 的前状态可以是:卖出且过了冷冻期 和 今天冷冻期 中的最大值;
今天卖出 的前状态:只能是 已经买入 ;
今天冷冻期 的前状态:只能是 今天卖出。
15日
714.买卖股票的最佳时机含手续费
只需要一步,卖出的基础上减去手续费,如果大于之前买入的金额,就进行更新
16日
300.最长递增子序列
主要思考方向,dp[i]为当前位置递增的次数,状态转移应该根据:若满足递增,找到历史所有位置的递增次数最大的那一项+1
注意,答案不一定在dp[]最后面,所以需要遍历整个dp[]找到最大值(此处返回答案需加一,因为单独一项视为递增次数为1)。
674.最长连续递增序列
相比于300,不需要找历史最大,状态转移只需要找到:若满足递增,上一个位置(dp[i-1])加一即为当前位置(dp[i])的递增值。
同样需要遍历整个dp[]找到最大值(此处返回答案需加一,因为单独一项视为递增次数为1)。
17日
718.最长重复子数组
使用二维dp时,注意需要状态转移的时候两个数组的索引都要加一,在打印出来的dp数组中体现出:上一个状态应该左上角(i-1, j-1)的位置。
使用一维滚动dp时,注意内层需要从大到小遍历,因为检查重复子数组的顺序从水平上看是从左往右的,且如果不相同会直接将该位置覆盖为0,所以如果不是从大到小遍历,历史相同序列的累加次数会被清0,假设下一个数字依然是最长重复子数组的一个,但是上一个状态已经被覆盖为0了,进行状态转移时dp[j] = dp[j - 1] + 1;最大值永远为1。
class Solution {
public:
int findLength(vector<int>& A, vector<int>& B) {
vector<int> dp(vector<int>(B.size() + 1, 0));
int result = 0;
for (int i = 1; i <= A.size(); i++) {
for (int j = B.size(); j > 0; j--) {
if (A[i - 1] == B[j - 1]) {
dp[j] = dp[j - 1] + 1;
} else dp[j] = 0; // 注意这里不相等的时候要有赋0的操作
if (dp[j] > result) result = dp[j];
}
}
return result;
}
};
18日
1143.最长公共子序列
搞清楚dp[i][j]的含义是:字符串1的前i-1项与字符串2的前j-1项的最长公共子序列,所以当text2[i-1]==text1[j-1]时,当前dp[i][j]值为前一个状态dp[i-1][j-1]再加一
并且如果不满足text2[i-1]==text1[j-1],则需记录(延续)历史最长状态
19日 53.最大子数组和
简单,好像做过,考虑上一状态加上当前状态和当前状态直接取最大…
1035.不相交的线
和18日的解法一样
20日
392.判断子序列
一次即可
21日
115.不同的子序列
(在 s 的 子序列 中 t 出现的个数)
当行为s,列为t时,转移方程为dp[i][j]=dp[i-1]j+dp[i-1]j-1;
初始化:s为空(对应row为0)时,初始化dp[0][j]=0;t为空(对应col为0)时,dp[i][0]=1;
记得开ULL
unsigned long long dp[1001][1001]={0};
for (int i=0; i<s.size(); i++) dp[i][0] = 1;
for (int j=1; j<t.size(); j++) dp[0][j] = 0;
可以改写成:
vector<vector<uint64_t>> dp(s.size() + 1, vector<uint64_t>(t.size() + 1, 0));
for (int i = 0; i <= s.size(); i++) dp[i][0] = 1;
22日
583.两个字符串的删除操作
(dp展开图一定要注意初始化,和转移规则,不要一开始画错了)
递推公式:
如果当前i-1和j-1字母相同,直接等于dp[i-1][j-1],表达的意思是不需要删除多余元素,直接跳过;如果当前i-1和j-1后字母不相同,在三个状态中取最小值,分别为[i-1][j-1]+2(可省略,与后面两个重复), [i][j-1]+1, [i-1][j]+1;(此时如果前面的状态有相同字母并跳过了+1,那么对应方位的数字一定是最小的那个)
初始化:
此时word的长度就是需要删除的元素数量
23日
72.编辑距离
较简单,画出dp展开图就容易推出状态转移方程,复习时可再次思考三个状态转移分别具体的含义
24日 647.回文子串
重点在于状态转移表达,一个回文串上一个状态只有两种可能,[left+1][right-1]的串是回文串或者不是回文串,所以当前状态的字符相同时,须判断上一状态的字符串是否为回文串,或者是一开始时,left==right || left+1=right时,代表此时的字符串一定是回文串(题意要求一个字符就算回文串,两个字符时相同即为回文串);
初始化:题目没其他要求,当作0的时候不是回文串,即为false;
遍历顺序:画一画dp展开图就知道了,当前状态是从左下角状态推移而来,从右下角开始遍历,内层正常顺序,初始化为外层i的位置。对角线均为1.
25日 516.最长回文子序列
初始化:单个字母长度需要初始化为1,对应 dp[i][i] = 1;
遍历顺序:因为初始化时考虑了单个字母,又因 i 可以等于0,而上一状态中的索引可能有 j-1 ,所以为了防止越界,内层遍历j时初始化为 i+1 。
状态转移:如果当前两个“指针”指向的字母相同,则当前状态等于上一状态(dp[i+1][j-1])加2(此处是因为求的是回文子序列,所以不用考虑中间有其他字母影响回文串,只需要判断其存不存在),如果不相同则取历史最长
26日 376.摆动序列
考虑清楚边界情况
27日 55.跳跃游戏
需要注意一次跳最远不一定是最优解(总体跳最远),需要依次对比,当前已经覆盖的区域index应该在当前能覆盖的区域i+nums[i]和上一步能覆盖的最远区域index中取最大值,如果覆盖的区域大于nums的长度index>=num.size()-1,则返回true,否则如果 i 大于已经覆盖的区域index,则返回false;
77.组合
递归传入起始位置应该是i,可以加上剪枝操作,如果剩下的数字不够组成k个数的组合,则直接去掉该操作,i <= n变为k-temp.size()+i <= n+1
为什么有个+1呢,因为包括起始位置,我们要是一个左闭的集合?
28日
1465.切割后面积最大的蛋糕
思路简单,注意max和%都需要相同类型。
45.跳跃游戏 II
需要注意覆盖范围仍然要判断,分成两个覆盖范围,分别是当前移动下标(i)所在位置的最远覆盖范围,和依然包含移动下标(i)的历史最远覆盖范围;当历史最远覆盖范围包含了终点nums.size()-1,直接返回 ans ,当下标(i)到达历史最远覆盖点后,说明当前这步不能直接达到终点,需要更新历史最远覆盖距离为当前移动下标(i)所在位置的最远覆盖范围,并且 ans++。
29日
1005.K 次取反后最大化的数组和
注意负数取正后需要重新判断数组大小顺序
134.加油站
只需找起点:可以判断区间补充油量和消耗油量的大小,如果补充油量大于消耗油量,则继续累加下一站位置,如果小于了,则说明起始位置最少也是开始当前位置的下一站。
最后判断总累计的油量是否为负,如果是,那么不可能存在起点,直接返回-1;如果否,就返回之前记录的start。
30日
135.分发糖果
因为当前状态会影响所有的历史状态,所以需要两次遍历,分别从前往后再从后往前,第二次更新数组的时候取最大值,此时的最大值即为被影响后的应当取的数值。
31日
860.柠檬水找零
简单模拟
406.根据身高重建队列
挺好的贪心,模拟;先按身高从大到小排序,相同的身高情况下,按k从小到大排序;之后按照顺序依次插入数值,插入位置为k的大小,因为每个people[i] = [hi, ki],相同k的情况下,一定是遵循身高排序从小到大的顺序(从左到右),每次插入的people[i]必定满足ki的要求,
贪心(找规则),多试试
2023.9.17
2023.9.18
5017.垦田计划
首先分析题目,已知待开垦的区域总数(n)、顿顿手上的资源数量(m)和每块区域的最少开垦天数(k),第i块区域开垦耗时(t)和将耗时缩短 1天所需资源数量(c)。开垦时间以最久的一块地为标准,目标找到所有田的开垦时间最大能缩短到哪一天,起始有n块田,分别需要t天开垦完、需要c个资源单位缩短一天的时间。
使用二分,左为题目限制至少需要的开垦天数k,右为题目给出的最多开垦天数1e5,二段性:当mid天时,res+=(t[i]-mid)*c[i](即要缩短到mid天时所需要花费的资源数)与实际拥有的资源m比较大小;如果res大于m,则说明资源不够,需要将mid右移(增加mid,降低res);反之如果res小于等于m,则说明手上资源可能是仍然充足或者是刚好满足缩短所需资源数,所以需要将mid左移
2023.9.20
5165. CCC单词搜索
首先分析题目,已知要在矩阵中找到目标单词,出现的形式包括:横、竖、斜或者转弯一次(直角转弯)。题目数据量80w,可枚举。
使用DFS和枚举,已知当枚举找到目标单词首字母后,第二个字母可能存在的方位为8个,所以在两层遍历找首字母的基础上,多一层遍历八个方向,在判断函数中,不但要判断字母是否匹配,还要判断两层遍历的变量是否越界,并且使用偏移量的方式判断方向
2023.9.21
5166. 对称山脉
首先分析题目,已知求i座连续山脉的最小不对称值。不对称值计算方法为首减尾,左加一右减一后重复首减尾,直到左右相同位置;思路,正常枚举是n3超时,所以需要压缩至n2,外层循环的i意思是以第i座山为中心,内层第一循环表示奇数座山间(窗口为奇数个)的不对称值,第二循环表示偶数座山间(窗口为偶数个)的不对称值,内层第一个循环依次为1座山的最小不对称值,3座山的最小不对称值等,内层另一个循环同理(最长回文子串)
2023.9.23
2023.9.24
5179. 分组
利用哈希表,减少搜索时间,将三个被分到同一组的学生分配到同一个value值;由此想同一组的学生是不同value值,则答案加一,不想同一组的学生是同一value值,则答案加一
2023.9.25
5180. 正方形泳池
最差的枚举情况为n4,可优化到n2,即遍历一次横向,上下边界遍历中更新(外层重新初始化,内层遇小变小),再将x和y对换位置(翻转矩阵),重新进行n2的遍历操作,最后两次遍历的结果取最大即为答案。
1.因在外层遍历时,为左边界,不考虑纵轴位置,所以同一列的树仅遍历第一次,后面同一列树进行continue;
2.因为一共进行两次遍历,所以当发现矩阵被上下边界限制的时候可直接退出内层循环,将矩阵翻转后的第二次循环会考虑到第一次循环跳过的情况;
2023.9.27
5181. 好四和好五
同leetcode凑硬币。
2023.9.28
5183. 好三元组
分析题目,因为符合题意的三角形过多,故采用1-的形式计算,圆周上有 c 个整数位置点,一个长度为 N 的整数序列, N 在 c 内,故总方案 res 为 Cn3,因为圆不好用序号分析,所以使用 破环成链 ,将周长为 c 的圆,变为长度为 2c 的线段;然后,使用前缀和方法将前i个数字的个数和记录在数组内(方便后面计算组合数);,设 t 为第i个位置存在几个数字(如果在那长度为 N 的整数序列内没有这个位置时,t 为0),设 sum 为第 i 个位置到 i+c/2 个位置的区间数字的个数和,再从0开始遍历不符合题意的三角形:
- 此时遍历到的i位置只存在一个数字:Ccnt[i]1 * Csum2;
- 此时遍历到的i位置存在两个或以上个数字:Ccnt[i]2 * Csum1;
- 此时遍历到的i位置存在三个或以上个数字:Ccnt[i]3。
如果此时 c 为奇数,即 i 与 i+c/2 不对称,此时 res 减去以上三角形即为答案;若此时 c 为偶数,则 i 和i + c / 2是对称的,在此起名 a,b ;所以当遍历 i 的时候会发生:
- a先作为t,右半圆包含b,所以右半圆选两点可能都选到两个b,
- 接着遍历加c/2后到了b作为t,右半圆包含a,所以右半圆选两点依然可能选到2个a,
所以此时重复减去这部分,需要加回来之后,即为答案
2023.9.29
2023.9.30
2023.10.1
2023.10.2
5201. 午餐音乐会
三分模板:
int l = 0, r = 1e9;
while(l<=r)
{
int midl = l + (r - l) / 3;//往回缩小三分之一
int midr = r - (r - l) / 3;
if (check(lmid) <= check(rmid)) r = rmid - 1;//如果左边的数小于右边,
//那么左边更接近最小值,就可以直接更新r;
else l = lmid + 1;
}
2023.10.3
5202. 日常通勤
图的问题,思路大概是,遍历每一站开始步行:1,第一站开始步行即为一直步行不坐地铁;2,第i站开始步行即为从第一站坐地铁到第i站然后步行至终点;3,坐地铁到终点
代码不太懂
2023.10.4
5218. 密室逃脱
很好一道dfs,回溯题,位置用二维数组存;权值为索引,保存对应的x,y位置(可能存在多个),为结构体类型的vector
4958. 接龙数列
蓝桥杯14届题E,好题,dp
相似(leetcode):300.最长递增子序列
2023.10.5
5219. 猜测短跑运动员的速度
注意时间需要从小到大排序,因为时间是连续的,不能将跨时间的路程差当作有效数据
2023.10.6
5221. 交换座位
类似“整理书籍”,需要先分析出,一共只有两种座位的排列情况,分别是abc或者acb,接下来在读入数据后,先得到三个字母转化成012,分别求出前缀和,及三个字母分别有多少个,再枚举n种位置,每个位置得到的最小换座次数:
首先以i为起始位置,接下来将a的个数当作a的区间,计算该区间(起点为i,长度为a的数量)内b的个数(b在该区间的前缀和的差值);同样道理,a和b互换,算出该区间之后的区间(起点为i+a的数量,长度为b的数量)内a的个数(a在该区间的前缀和的差值),得出second_in_first和first_in_second,(PS·如果长度超出一圈的范围,则区间内字母的个数计算应该改成:圈的最后一点的前缀和-起点前缀和+(起点+长度-n)的前缀和;可以想象出正是最后一段加头一段的字母个数;)同样道理,在计算c分别在a,b区间的个数后,对应相同两个区间的不同字母个数分别相加,总的移动次数为:not_A+not_B−min(first_in_second,second_in_first);即a区间内其他字母的个数加b区间其他字母的个数,因为a区间内的b可以直接和b区间内a进行互换,这样总的操作次数就可以减少一次,所以至多选择first_in_second和second_in_first中最少的个数作为直接互换次数,减掉后,即为当前i起始位置的最少移动次数。
遍历完n个位置后即可得出最少移动次数的答案。
2023.10.7
5220. 搜索字符串
字符串哈希
求某个字串的哈希值长度模板:
const int P=131;
char b[n];//字符串
unsigned long long p[N], h[N];//h[]存字符串哈希值,p[]存p的次方
for(int i = 1; i<=m; i++)
{
p[i] = p[i - 1] * P;
h[i] = h[i - 1] * P + b[i];
}
unsigned long long get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
思路明白了,代码需要重新写
11月
1日
452.用最少数量的箭引爆气球
主要注意两种情况,如果当前状态的起点大于上状态的终点,即ans++;,如果当前状态的起点小于上状态的终点,需要更新当前的终点和上状态的终点的重合区间,即找两个终点的最小值
2日
435.无重叠区间
记录重合的最短右边界
3日
763. 划分字母区间
思路很重要,先存下每个字母的最远距离,因为一个字母只能出现在一个片段内,所以可以确定当遍历到字母对应的最远距离的时候,下一个位置即为切片位置;
但是在此基础上,可能存在一开始遍历到的字母的最远距离 **< **没找到最远距离前的后来遍历到的字母的最远距离,此时需要更新目标–最远距离为后来遍历到的字母的最远距离;
最后注意,须同时判断是否更新最远距离和是否到达最远距离。
4日
56. 合并区间
注意,覆盖范围的更新时机,可以不用弹出上一个数组,直接改上一个数组的右边界
5日
738. 单调递增的数字
两个函数:to_string(n);和stoi(strNum);,方便处理数字,不用考虑位数,也不用考虑如何替换该位的数字,随机访存,思路较简单,遇到的非递增的就标记该位且该位上一位减一,最后标记往后覆盖9
6日
968. 监控二叉树
把所有情况都列出来就容易分析了,如:
- 0:该节点无覆盖
- 1:本节点有摄像头
- 2:本节点有覆盖
中放摄像头:(返回1)
left == 0 && right == 0 左右节点无覆盖;
left == 1 && right == 0 左节点有摄像头,右节点无覆盖;
left == 0 && right == 1 左节点有无覆盖,右节点摄像头;
left == 0 && right == 2 左节点无覆盖,右节点覆盖;
left == 2 && right == 0 左节点覆盖,右节点无覆盖。
中已被覆盖:(返回2)
left == 1 && right == 2 左节点有摄像头,右节点有覆盖;
left == 2 && right == 1 左节点有覆盖,右节点有摄像头;
left == 1 && right == 1 左右节点都有摄像头。
中未被覆盖:(返回0)
left == 2 && right == 2 左孩子有覆盖,右孩子有覆盖
(此时中有可能是头节点,所有最后须判断头节点是否无覆盖,是则res++,否则直接返回res)
7,8日
发烧晕两天
9日
216. 组合总和 III
注意,可剪枝,循环剪枝记得加一
10日
复习括号形式创建二叉树,注意:利用栈指针进行回退操作
11日
复习泛型二叉树,前中后递归遍历
12日
复习建立多叉树
13日
复习递推遍历二叉树
14日
复习统一迭代法
15日
复习层序遍历,包括递推递归
16日
106. 从中序与后序遍历序列构造二叉树
首先后序遍历最后的肯定是最上面的中间节点(即最后一个遍历的节点为根节点),中序遍历时,根节点的左区间即为左子树,右区间即为右子树,所以下n层递归时优先找中间节点,即为后序遍历最后索引-n的位置,找到后直接挂在上一个节点的左/右字节点,以此再次分割中序数组、挂节点。
17日
654. 最大二叉树
先找到最大的值,构建节点,左右子树分别递归,递归函数返回值为节点,故最后返回时自动将对应节点挂好
18日
617. 合并二叉树
使用层序加递归解决,注意判断两树某位置有空节点时,直接将2树的节点挂在1树的节点,这样这个节点以后的节点不需要进行层次遍历合并了,直接返回就是正确的
19日
98. 验证二叉搜索树
需注意:节点的左子树只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。也就是子树所有节点都需满足条件
在递归调用左子树时,需要把最大值改为根节点的值,递归调用右子树时,需要把最小值改为根节点的值。
20日
530. 二叉搜索树的最小绝对差
501. 二叉搜索树中的众数
需要记录上一个节点的状态,因为是BST,所以按照遍历顺序,可以得到历史最小和当前上一个节点(此处并不指父节点,而是上一节点)中最小值,or计数+1
21日
236. 二叉树的最近公共祖先
首先考虑查找顺序,因为是查找祖先,所以应该是从下往上,所以使用左右中顺序的后续递归遍历;考虑递归函数的返回值,因为记录的是节点,所以选择返回节点;显而易见当找到p或者q节点时直接返回当前节点,如果没找到则会一直返回nullptr,因为遍历整棵树,所以要将找到的祖先往上传,故左右都为空时,返回父节点,左右有一个为空时返回不为空的节点,或者直接返回nullptr
22日
235. 二叉搜索树的最近公共祖先
两种解法,可以和236一样,也可以从搜索树的特性出发,从上往下,遇到的第一个节点的数据域满足位于p,q之间,即假设p大于q,当前节点的值:x,满足q<=x<=p时,当前节点即为最近公共祖先。(注意搜索树性质,同一颗子树内所有节点均满足大于or小于父节点)
23日
701. 二叉搜索树中的插入操作
不需要特殊处理
450. 删除二叉搜索树中的节点
思路不难,但注意最好先从简单情况开始书写,不然在没有动笔记录情况的时候容易写绕进去。
24日
669. 修剪二叉搜索树
比较简单,在排除不符合的节点的时候,可以排除一个就进入一次递归(判断下一个是否符合),也可以利用while直接找到第一个符合条件的节点,再进入正常逻辑下的递归。
25日
108. 将有序数组转换为二叉搜索树
要注意,分别递归左右子树时,直接代入int mid=left+((right-left)/2);,因为是两个区间都要取,所以此时分别的左右区间为:left, mid-1,mid + 1, right
26日
538. 把二叉搜索树转换为累加树
考虑问题先考虑最小情况,即此时从下往上遍历时,只需累加当前节点的值和右子节点的值即可
27日
797. 所有可能的路径
dfs的框架像回溯框架,终止条件为找到终点,遍历当前节点可以去的节点(此时为graph[start].size())。
28日
200. 岛屿数量
dfs:
大致思路,主函数遍历整张地图,如果遇到陆地且未被标记为到达过,及进入dfs搜索整块陆地,
dfs,利用四个方向的偏移量进行位移
注意:
x和y代表的是行和列,在图上是高和宽,和正常坐标系的xy是反的;
‘1’是char类型,”1”是string类型;
解题思路大概是先遍历地图,遇到陆地就调用dfs将这块陆地全部标记上”访问”,并将计数器++,遇到海就跳过,直到遍历完整个地图,此时计数器结果就是几块陆地
bfs:
利用队列记录周围可走陆地,一次性就会记录所有下一步可到达的陆地,下一步同样操作,直到队列为空(即上一步已经找不到任何可以走的下一步了,换个说法无路可走,最远距离就是上一步)
29日
695. 岛屿的最大面积
dfs:
做法和昨天的大差不差,补充:使用局部变量nx和ny,在每一轮循环和回溯的时候自动回退值,需注意什么时候是x什么时候是nx。
bfs:
同上。
30日 1020. 飞地的数量
思路正确,注意下小细节。
防止出现重复,故在主函数遍历时将最外围一圈排除(如果陆地到达最外围一圈,则不符合条件,可以离开网格,临时计数须置零);在中间遍历时,遇到陆地则需dfs,如果这块陆地能到达最外一圈,则将标志位记为true,同时继续搜索剩下同一块陆地;重复dfs,如果标志位不为空,说明不是飞地,临时计数加到答案计数内。
12月
1日 130. 被围绕的区域
思路正确,注意细节
另一种思路:可以先遍历周围一圈,将周围一圈连接的陆地全部替换成另一种标记(如’A’),然后再遍历整张地图,将所有O换成X(此时的O一定没有和周围一圈连接),所有的另一种标记(如’A’),替换回O
2日 417. 太平洋大西洋水流问题
遍历全图会超时,所以需要遍历周围一圈,左和上的dfs传入ao(二维bool),将能抵达左和上的地点标记为true,右下同理,传入po,标记为true;
最后遍历全图,如果同时满足ao和po说明满足题意,能到达两个洋,故push
3日 827. 最大人工岛
大体的思路是先标记每块陆地的编号key和面积value,然后再遍历海洋,此处海洋四周的陆地的编号key加起来,找到最大的value
4日 127. 单词接龙X
不要局限于dfs,找最短路径应该用bfs,为了方便查找相应字符串是否在字典内,使用u_set代替vector存储字典;在字典内找到对应字符串且没记录过(防止后面重复找到字符串后,最短路径被覆盖)时,使用u_map存储字符串+到达该字符串的路径长度;为了保证相邻字符串相差一个字母,直接分别枚举每一位(如3位字符串一共枚举3*26次),直到在字典找到endword(直接返回路径长度+1,因为此时的路径长度一定是到达当前字符串所需要的最短路径),或者找到下一个存在于字典的字符串,并和当前路径长度存入u_map。
5日 841. 钥匙和房间
比较简单,做的时候用了bfs,有点小错误,忘记将0号房间置为true到达过;
6日 463. 岛屿的周长
因为只有一个岛屿,所以只需要每次考虑岛屿周围的水域长度即可,直到遍历完地图
7日 1971. 寻找图中是否存在路径 并查集
并查集
注意并查集模板,无向图中,把父节点理解为一个代表节点也可以
第一步 初始化:将每个节点的父节点设为自己
// n为节点数量
vector<int> father=vector<int> (n, 0);
for(int i=0; i<n; i++)
{
father[i]=i;
}
第二步 查询:找根节点 (祖先)-> 找父节点是自己的节点(即为根节点),所以子节点的父节点都将递归设置为根节点(路径压缩) ```cpp int find(int u, vector<int>& father) {
return u==father[u]?u:father[u]=find(father[u], father); } ```
第三步 合并:分别找到`u`和`v`各自的根节点,如果`u`和`v`的根节点是同一个,则说明`u`和`v`在一个集合内,可达,不需要合并;如果不是同一个根节点,则将`v`(或者u)的父节点设置为`u`(或者v),此时可看作`v`为`u`的子集。 ```cpp void join(int u, int v, vector<int>& father) {
u=find(u, father);
v=find(v, father);
if(u==v) return;
father[v]=u; } ```
第四步 查找:u和v是否在一个集合内 ```cpp bool IsSame(int u, int v, vector<int>& father) {
u=find(u, father);
v=find(v, father);
return u==v; } ```
8日 684. 冗余连接
注意father用节点数初始化时,需要加一;因为此处的图的根节点为1而不是0,edges[i][0]和edges[i][1]的值的范围是1到n
9日 685. 冗余连接 II
重要的是,按照树的性质,每个节点至多只有一个入度,若干的出度,所以先统计入度;由于树的节点数量等于边的数量,所以表明只有一条边被加入到原本的树中,即入度至多为1+1=2个;所以只需遍历记录edges[i][1]对应出现两次的边。
需要分两种情况讨论,第一种情况:存在入度为2的节点,说明这里的两条边必须删除一条,先试删除最后的边(在edges里较后出现的,题目要求多个答案取后面的),如果删除后仍然出现有向环,说明删错了,另一条边即为要删除的答案;第二种情况:不存在入度为2的节点,则说明多加的一条边一定加到根节点上了,这里一定存在有向环,所以只需判断增加哪一条边后出现有向环,则这条边即为答案
PS.记得在判断这两种情况的时,需要重新初始化father,再进行join
10日X 92. 递归实现指数型枚举 - AcWing题库
关键在于使用一个数组记录当前位数是否选择,最后当递归完所有位数时,再逐一打印被选择的位数,不要在中途考虑打印
11日X 94. 递归实现排列型枚举 - AcWing题库
应该选择用一个数组记录当前位数是否使用过,遍历初始化应该每次都从1开始;再用数组记录当前索引对应数字几
12日X 95. 费解的开关
注意步骤中可能是开灯也可能是关灯,输入用cin,防止空格,回车等符号
思路很重要,只需遍历第一行的所有开关灯情况,就可以得出是否能做到全关灯的结论;
因为第2行及以后,开关灯的依据变为:将上一行熄灭的灯**b[j-1][k]**点亮 -> 开关本行**b[j][k]**的灯;
最后判断是否能做到全关灯,仅需遍历最后一行是否有熄灭的灯(中间行的灯一定会被全部点亮),如果做到了就统计步骤数,并且如果多次做到需要使用min()取最小,如果最后得到的最小次数超过6,就将步骤数置-1,并cout
13日 93. 递归实现组合型枚举 - AcWing题库
一开始卡了很久,因为把start(开始位置)和size(当前方案的长度)搞混了,而且把递归需要传递的开始位置也写错了;搞清楚每个参数的意义
结束条件应该为当前方案的长度size等于需要的个数m的时候,遍历条件应该为当该位的数字没被选中时,选中它并继续向后递归,注意传递size+1
循环可以剪枝优化:38ms,没优化:145ms
另一种思路:枚举每个位置的不同选法
14日X 1209. 带分数
PS数组大小开15会寄,可能哪里乘超了,记得开大点,反正如果开大了没用到,不会被分配空间
注意题意,后面的分数不是整除的,思路在于将1~9分为三个部分,分别为整数部分,分子和分母,等于在这三个部分的基础上做全排列,因为需要加起来等于n,公式:n=a+b/c,所以可以将公式转换为b=n*c-a*c;使用两个递归函数(a的dfs节点为c的dfs),全排列出a和c的放法,最后判断算出来的b是不是刚好满足为剩下的数字组成的(记得开backup记录a和c的情况),满足则ans++,否则直接返回
剪枝:三个部分必须有值,所以如果有部分小于等于就不用进行之后的判断了
15日 116. 飞行员兄弟 - AcWing题库
小问题:
如果将 count 定义为自己的一个全局变量,而 C++ 标准库中也有一个名为 count 的函数,导致在代码中调用 count 时发生了歧义(ambiguity)。C++ 编译器无法确定是调用全局变量还是调用标准库函数,因此报错。
用暴力的方法做出来了,但是一开始思路有问题,
想好再动笔,对于一个状态位,有多个位可以影响到它,所以每一行的状态不止与相邻行有关,每一个状态位都和对应横行纵行的状态位有关;
16日 1208. 翻硬币
稀里糊涂写出来了,然后思考为什么:题目说仅可以翻转相邻的两个硬币,可看为:当前硬币的状态可被上一个硬币改变,所以只需要遍历一次,发现不一样的状态时进行翻转,并影响下一个硬币,直到最后,因为题目说一定有解,所以遍历到最后的翻转次数就是答案
17日X X 789. 数的范围
l+r>>1 等效:(l+r)/2
二分两次边界才是最优,因为可能目标值左右边界相距甚远;利用分界点的特性:if(arr[mid]<num) left=mid+1;else right=mid;
此时的right一定是左边界点
同理右边界,当left==rifht时,left左部分均小于等于目标值,右部分严格大于目标值。注意,当想要在数组中找到大于或等于给定值的第一个元素时,比如如果需要找右边界,也就是要更新左节点,需要在计算mid的时候,»1前+1,防止被舍去
92. 递归实现指数型枚举 - AcWing题库
dfs传入的参数应该为需要判断是否输出的当前位数,有两种状态分别为选和不选,等于说,更新当前状态然后dfs下一层(下一个数字),当dfs到最后一层之后(>),输出
18日X 790. 数的三次方根
注意数据范围从负到正,所以n不一定大于-n;
浮点数(6位)的loop条件:right-left>1e-8;
注意更新left和right时都直接更新为mid,防止直接加一会越过最优解
94. 递归实现排列型枚举 - AcWing题库
一定要思考好逻辑思路再写代码逻辑,不然写出来的代码逻辑混乱,只要一开始逻辑思路是对的,代码一定不会写错
19日 795. 前缀和
比较简单,注意下左边界应该减一后才是需要被排除的大小,因为左右边界均大于0,所以不用异常判断
95. 费解的开关
注意:
这是因为在这个问题中,需要对每个字符进行单独的操作。在C++中,std::string是一个字符数组,但它被封装成了一个对象,所以不能直接对std::string的每个字符进行操作,而char数组允许直接访问和修改每个字符
如果使用了std::string数组b[5]和backup[5],然后试图通过b[nx][ny]来访问每个字符。但是,这实际上是在访问std::string对象的字符,而不是字符数组的字符。这可能会导致一些未预期的行为,比如无法正确地翻转字符(从’0’到’1’,或者从’1’到’0’)
如果改为char b[5][5], backup[5][5];后,b和backup现在都是字符数组,就可以直接访问和修改每个字符
当需要对每个字符进行操作时,使用字符数组通常会比使用std::string更方便,因为字符数组允许直接访问和修改每个字符。
**
20日 796. 子矩阵的和
容斥原理,当前位置的前缀和是以当前位置为右下角,左上角为原矩阵的左上角;计算差值只需b[x2][y2]-b[x1-1][y2]-b[x2][y1-1]+b[x1-1][y1-1]
93. 递归实现组合型枚举 - AcWing题库
递增,记录start,往后选就完了
21日 730. 机器人跳跃问题 - AcWing题库
当更新条件为r=mid-1的时候,mid须加一;
注意题目的数据范围,本题可能会爆int和longlong,所以当值已经大于当前最高高度时,一定能通过,故直接返回true即可
1209. 带分数
注意判断中,b也不能含有0,每一次不单要判断选中数字,也要判断非0
22日 1221. 四平方和
一开始的思路是,二分最后一个位置,找到后,再二分前面的位置,大于目标值则重置当前位置和之前位置,再次二分,不更新左节点,只更新右节点,但是这样算出来应该有点问题,得到的答案不一定是最后一位最大,
思路可以从暴力开始想起,可以使用哈希,先on2算出最后两位可能的所有平方和计入hash table,然后再算前两位的平方和是否符合四位相加为n,是的话直接打印并返回,因为前两位是从小到大枚举的,等效后两位从大到小选择
23日 1227. 分巧克力
注意,不一定每块巧克力都最少给人一块,因为可以极端来想,有一块1*1的巧克力,但实际最后可能用不上
24日 99. 激光炸弹
注意:不同目标可能在同一位置。
题目中的坐标包括(0, 0),但是前缀和中,计算公式为Sr-Sl-1,所以需要将题目的坐标xy均加一,常规计算前缀和,然后枚举所有可能取最值即可(有时候acwing抽风一直ac不了,刷新一下)
25日 1230. K倍区间
暴力简单,但是超时;
只需on: ans+=c[A[i]%k];
c[A[i]%k]++;
原因:如果 A[i] 和 A[j] 在对 k 取模后余数相同,那么说明这两个位置之间的子序列和是 K 的倍数。假设余数为 r,那么 A[i] % k = r,A[j] % k = r,所以 (A[j] - A[i]) % k = 0,即子序列和是 K 的倍数。
790. 数的三次方根
94. 递归实现排列型枚举 - AcWing题库
789. 数的范围
92. 递归实现指数型枚举 - AcWing题库
26日 1205. 买不到的数目 - AcWing题库
结论题:(n-1)*(m-1)-1为最大取不到的数
但是可以用暴力从0开始搜到100000之类的去搜索,能混分
27日 1211. 蚂蚁感冒 - AcWing题库
脑筋急转弯,分类讨论,不用模拟,如果感冒蚂蚁向右:右侧向左全感染,如果存在右侧向左,则左侧向右也全感染,感冒蚂蚁向左同理
796. 子矩阵的和
28日 背包分析 1216. 饮料换购
简单题,简单数学计算
29日 2. 01背包问题
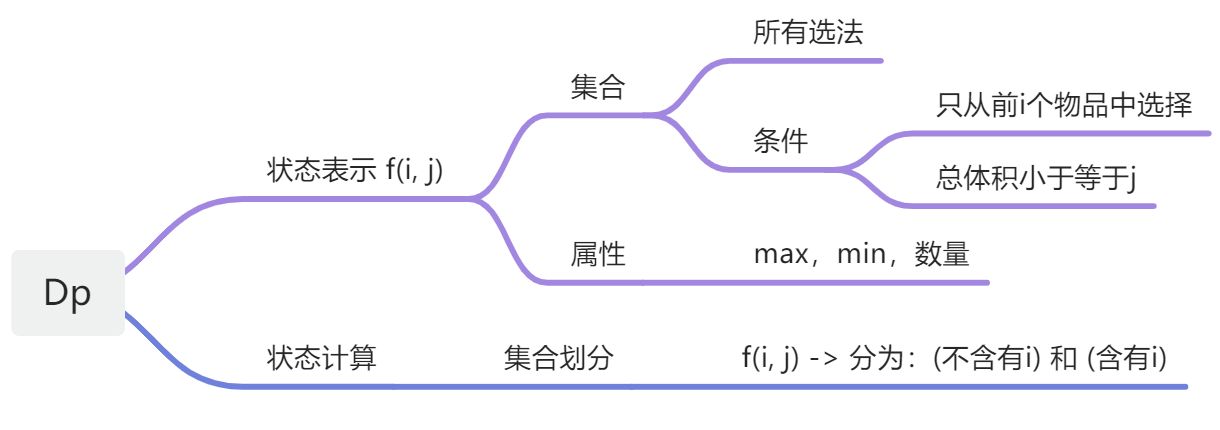
状态转移方程:上一个容量的最大价值和当前容量减去当前物品的重量(为了放入当前物品)后的最大价值加上当前物品的价值取最值
30日 1015. 摘花生
较为简单,状态转移方程为左和上取最大
895. 最长上升子序列
较简单,考虑上一个状态是前面所有状态的最大值
31日XXX 1212. 地宫取宝 - AcWing题库
使用闫氏分析法!分析出要四维dp,