2021 L3
"Building ft storage"指构建分布式系统中的 fault-tolerant(FT)存储。在分布式系统中,FT存储是指能够在组件或节点发生故障时保持系统可用性和数据一致性的存储系统,这意味着系统能够在硬件故障或网络分区等问题下继续运行,并且不会丢失数据或使数据不一致;
难点:需要高性能 -> 需要跨服务器对数据分片 -> 数千台服务器可能个别出现宕机(换句话说持续会发生错误) -> 需要容错性 -> 复制多份数据 -> 可能导致数据一致性的问题 -> 需要持久性的协议(影响系统容量和分片数设计
并发问题 错误问题
GFS
关键属性:
- 大:大规模数据集;
- 快速:自动分片到多个磁盘,支持并发读;
- 全局的:共享的,即应用程序看到的都是同一个文件系统;
- 容错:自动恢复;
master:
- 文件名到块句柄数组的映射关系,维护在内存中,需要持久化保存;
- 块句柄中有版本号(持久存储)和块服务(chunkserver)列表(内有块的复制),主/次要副本,释放时间;
主要副本:
- 负责协调对应数据块的所有读取和写入操作,包括客户端的读取请求和写入请求,检查租约等;
- 通过协调所有操作,确保所有副本之间的数据一致性,即使在面对网络延迟或节点故障时也能保持数据的一致性;
版本号:
- GFS 中的每个数据块都有一个关联的版本号,用于标识该数据块的当前版本,当数据块被修改时,其版本号会增加,以反映出数据的变化;
日志(存入持久存储中:名称空间发生更改、在GFS创建新文件、改变文件映射块句柄的关系) + 检查点(同样存入持久存储中,是系统周期性地创建的一种快照,记录了系统的状态,以便在需要时快速恢复);
写入持久存储后才会响应client;
租约:Lease,是一种用于协调并发访问的机制,它允许客户端对数据块进行独占式的访问,并防止多个客户端同时对同一数据块进行写操作;
租约流程
- 当客户端需要对数据块进行写操作时,它首先向 Master 请求获取该数据块的租约。
- Master 接收到租约请求后,会将租约授予请求的客户端,并设置一个租约超时时间(Lease Timeout)。在租约超时之前,该客户端可以独占地对数据块进行写操作。
- 在租约的有效期内,其他客户端仍然可以读取数据块,但不能进行写操作。如果其他客户端也需要对同一数据块进行写操作,它们必须等待租约过期或者租约被释放后才能获取租约并执行写操作。
- 客户端在完成对数据块的写操作后,可以选择将租约释放或者续租(Renew Lease)。如果客户端选择续租,它需要向 Master 发送租约续租请求,以延长租约的有效期。
client Reading:
- 发送请求到 master;
- master 响应 chunkhandle + 块服务列表 + 版本号;
- 缓存这个list;
- 从最近的chunkserver读取;
- chunkserver检查版本号(避免读取到过时的数据),通过则返回数据;
client Writing:append
- 发送请求,master查找文件名和块句柄映射后,通过块句柄查找块服务列表;即Master 接收到写入请求后,会确定主要副本,增加版本号(仅master维护),并向客户端返回相应的租约信息以及主要副本的位置信息;如果数据块的主要副本还不存在(第一次写入),Master 会选择一些数据节点作为该数据块的副本节点,并告知这些节点它们将是该数据块的次要副本;
- 客户端收到租约信息和主要副本的位置信息后,直接与距离最近的副本建立连接,并将需要写入的数据块发送给这个副本;数据流会以流水线的方式在精心挑选的 chunkserver 链(最近的副本节点)之间被线性地推送(边接收边发送到下一个副本节点);注意,次要副本节点并不会立即复制数据块,而是在接收到主要副本的写入请求后才进行复制操作;
- 主要副本接收并检查版本号和租约后才选择一个偏移量append数据后,告诉次要副本偏移量并开始append,主要副本和次要副本完成写入后(版本号同样持久存储),响应确认,master持久存储版本号)需要吗,主要副本也将更新的版本号返回给client;
- 如果有次要副本没有完成写入(即没有响应),主要副本会响应错误给client;
- 通常client会发起重试,此时步骤相同,只有偏移量会更新(不会重新利用之前写入的数据部分);
一致性
The Google File System master维护所有的文件系统元数据。这些元数据包括命名空间(namespace)、访问控制信息(access control information)、文件到块的映射,以及块的当前位置。它还控制整个系统的活动,比如块租约管理(chunk lease management)、孤儿块的垃圾回收,以及chunkserver之间的块迁移。master以心跳(HeartBeat) 消息的方式周期性地和每个chunkserver进行通信,下达指令并收集其状态信息。
master存储了三种主要类型的元数据: 文件和块命名空间,文件到块的映射,以及每个块的副本的位置。所有的元数据保存在master的内存中。前两种类型(命名空间和文件到块的映射)也会通过将变更记录到存储在master本地磁盘的操作日志(operation log) 而持久化保存,并且被复制到远端机器。使用日志能使我们简单、可靠地更新master的状态,并且如果发生master崩溃(crash)也不会出现不一致的风险。master不会对块位置信息进行持久化存储。取而代之,它会在master启动和chunkserver加入集群时询问每个chunkserver关于该chunkserver上的块(信息)。
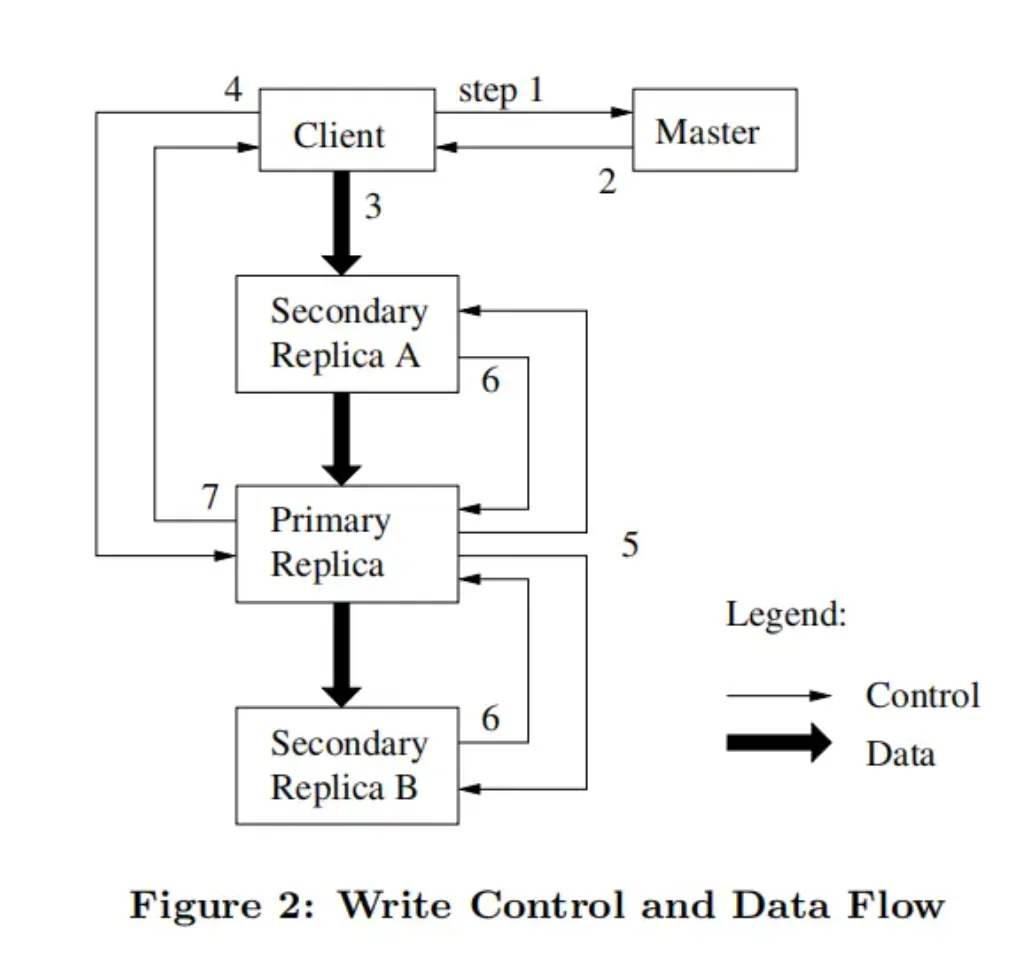
交互流程:
- 客户端询问 master 哪个 chunkserver 持有块的当前租约以及其它块的副本位置。如果没有 chunkserver 持有租约,master 会对它选择的一个副本赋予租约(图中没有展示)。
- master 回复 primary 的标识以及其它副本(secondary) 的位置。客户端会为将来的变更缓存这份数据。仅当 primary 不可到达(unreachable)或者 primary 回复其不再持有租约时,客户端才需要再次联系 master。
- 客户端把数据推送到所有的副本。客户端可以以任意顺序推送数据。每个 chunkserver 会把数据存储在内部的 LRU buffer 缓存,直到数据被使用或超期(age out)。通过从控制流中将数据流解耦,我们可以根据网络拓扑来调度开销较大的数据流,而不必关心哪个 chunkserver 是 primary,从而改善性能。Section 3.2 对此进行了更深入的讨论。
- 一旦所有的副本都确认收到了数据,客户端就会给 primary 发送一个写请求。这个请求标识了之前被推送到所有副本的数据。primary 为其收到的所有变更分配连续的序列号,这些变更可能来自于多个客户端,序列号提供了必要的编序。primary 依据序列号顺序将变更应用到自己的本地状态。
- primary 转发写请求到所有的从副本(secondary replicas),每个从副本以 primary 分配的相同的序列号顺序应用变更。
- 所有的从副本对 primary 进行回复以表明它们完成了操作。
- primary 对客户端进行回复。在任何副本上出现的任何错误都会报告给客户端。 在发生错误的情况下,写操作可能已经在 primary 和从副本的某个子集上执行成功(如果它在 primary 上失败,就不会被分配一个序列号和被转发)。这个客户端请求被当作是失败的,且被修改的区域停留在不一致状态。我们的客户端代码通过重试失败的变更来处理这样的错误。它在从写操作开头进行重试之前会在步骤(3)和(7)之间进行几次尝试。